A duplicate charge is one of the most damaging failure modes in card payments, and one of the most misunderstood. It is commonly diagnosed as a defect in application code. More often it is a structural consequence of how distributed payment systems behave under partial failure: the network drops at the wrong moment, the application loses certainty about whether an authorization completed, and a recovery decision is made as if that certainty still existed.
This post examines double charging as a state-management problem rather than a bug. It defines where in the transaction lifecycle certainty is lost, why the instinctive response — resending the request — converts a transient visibility problem into a permanent financial one, and how a read-before-write recovery model keeps the system aligned to a single authoritative record of what happened. The mechanisms referenced here (ISO 8583 reversals, idempotent transaction identifiers, and a deterministic recovery state machine) are drawn from the card-present transaction lifecycle as implemented in production POS and acquirer systems.
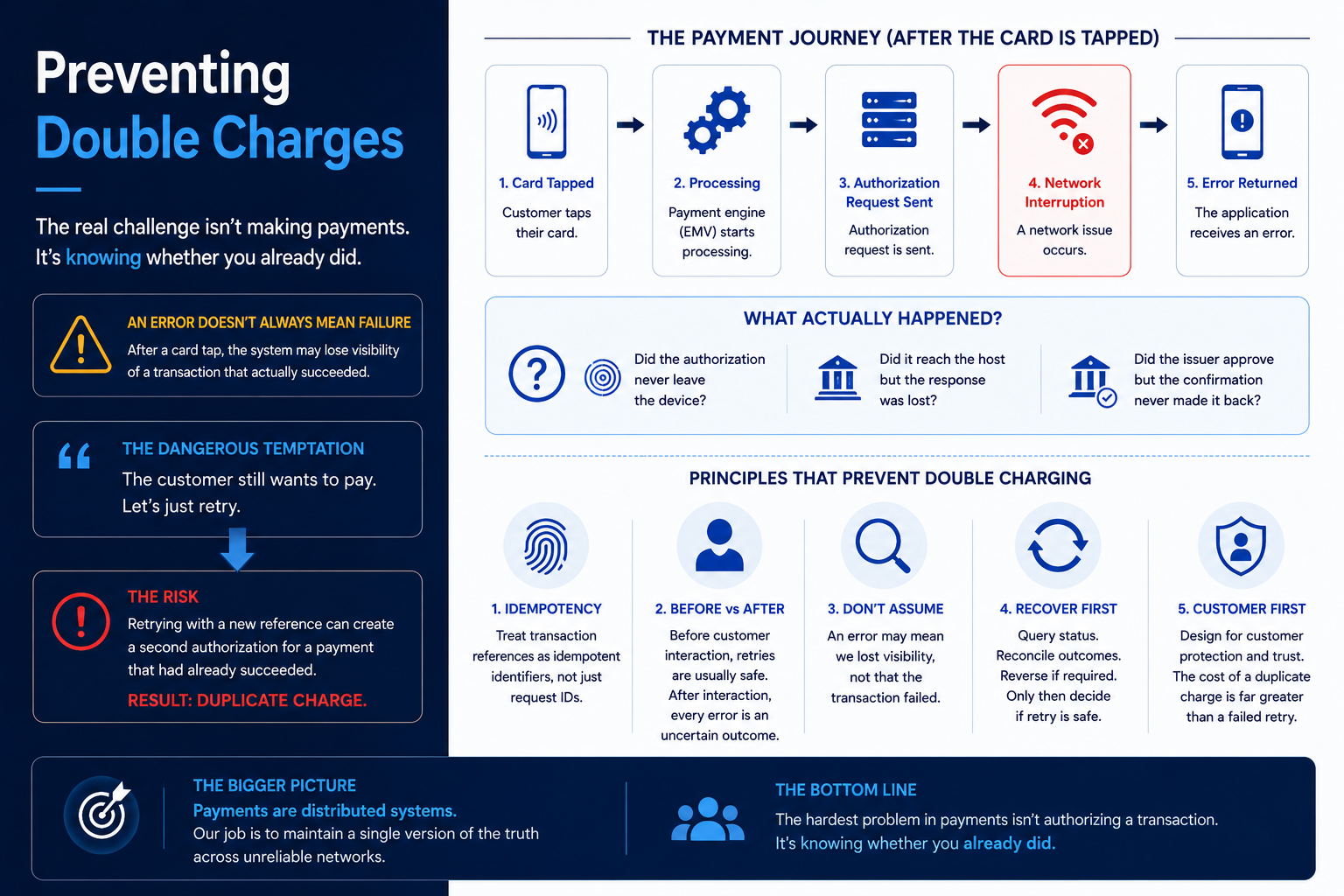
The moment certainty disappears
Consider the sequence at a terminal. The cardholder taps. The payment engine starts EMV processing and the card generates an Authorization Request Cryptogram (ARQC). The POS assembles an ISO 8583 request and sends it toward the acquirer. The transaction state machine moves to AUTH_REQUESTED. Then the network falters: a TCP connection hang, a dropped link, or an issuer response that never arrives inside the timeout window.
Timeouts at this stage are not a single event. They occur at different layers, and the book breaks them into tiers: connection timeouts (roughly 5–10s), request timeouts (20–30s), and issuer timeouts (30–45s). In HTTP-fronted acquirer stacks you may also see a 504 at the gateway. Whatever the layer, the application is left holding the same question: what is the actual state of this payment?
At that point three outcomes are all consistent with the error you just received:
- The request never left the device.
- It reached the host, but the response was lost on the way back.
- The issuer approved it, and the confirmation never made it to the merchant application.
The uncomfortable part is that the error itself does not tell you which one happened. This is the core idea, and it is worth stating plainly: in a distributed system an error is a loss of visibility, not a result. The money may already be moving while your application sits blind to the ledger.
Never assume an error means a transaction failed. Often it only means your application lost sight of the final state.
Why blind retries turn a visibility problem into a money problem
The instinct under pressure is to resend. The customer is standing there, they still want to pay, so the application fires the request again. On its own, retrying is not the mistake. Retrying wrong is.
A retry is only safe if the host can recognize it as the same payment. That recognition depends on the transaction reference. Backends deduplicate using a composite identity — in the book’s pattern, a key built from STAN, Terminal ID, and date — and return the cached outcome when a duplicate arrives, typically holding that record for 24–48 hours. If the retry carries the same reference, the host collapses it onto the original and you are protected.
If the retry carries a new reference, none of that protection applies. The host has no way to tie the second message to the first, so it treats it as a fresh transaction and may authorize it on its own. Now there are two authorizations for one intent. The visibility problem has become a financial one, and a trust one.
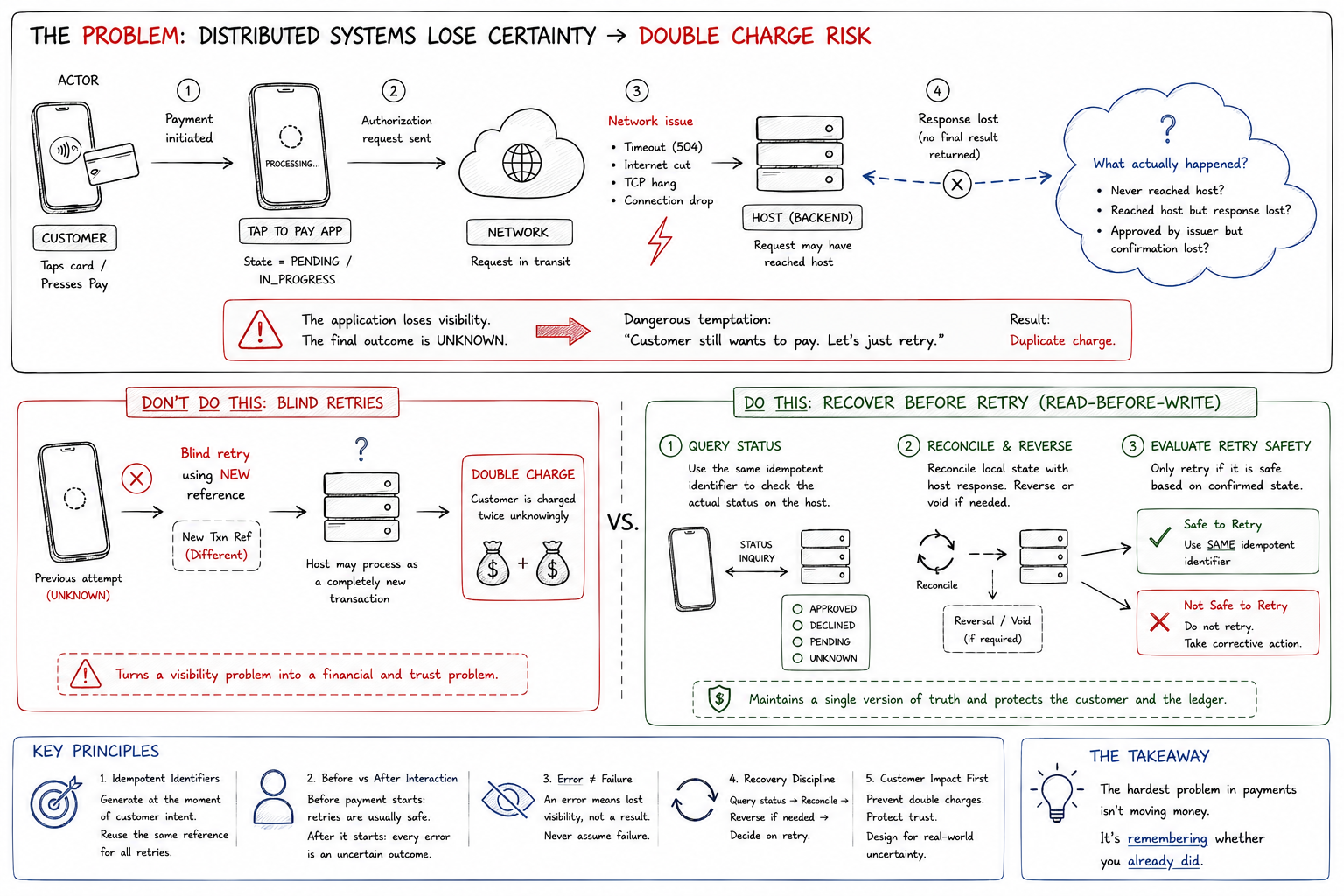
This is why I treat transaction references as idempotent identifiers, not request handles. The distinction sounds pedantic until you trace where the reference is born. If the identifier is generated at the moment of intent and persisted before the first send, it survives a lost response: the retry reuses it and the host’s deduplication does its job. If the identifier is minted server-side and the network drops before the client ever learns it, the client cannot reuse it, and idempotency is gone exactly when you needed it. The reference has to represent the customer’s intent to pay, not the server’s attempt to process.
Before and after the customer commits
Not every retry is dangerous, and treating them all the same is its own mistake. There is a hard boundary in the flow: before the customer interaction commits versus after.
Before the Pay action — while the user is still on the checkout screen and no authorization has left the device — retries are generally cheap and safe. Nothing has been put in motion. After the state machine moves to AUTH_REQUESTED or IN_PROGRESS, the rules invert. Past that line, any error is no longer a failure to be re-sent. It is an uncertain outcome that has to be resolved before you touch it again.
Most duplicate-charge incidents I have seen come from applying “before” logic after that boundary — reacting to a post-commit timeout with the same reflex that was harmless during checkout.
Recover before you retry: read-before-write
The discipline that replaces the blind retry is read-before-write. Instead of reacting to a timeout by sending again, you first find out what actually happened, then act on facts.
Query status. Use the idempotent identifier to ask the host for the real state of the payment. This is the mandatory read. The book leans on a deterministic recovery state machine for exactly this:
AUTH_REQUESTED → TIMEOUT → REVERSAL_SENT → REVERSED, so an uncertain transaction always lands in a defined place rather than limbo.Reconcile and reverse if needed. Align local state with the host’s answer. If the transaction sits in a state that could lead to a double charge, issue a reversal. In ISO 8583 terms that is a
0400(reversal request) or0420(reversal advice) that references the original via STAN, RRN, and the original data elements, releasing the authorization hold. In EMV flows the reversal may echo the original Field 55 cryptogram data so the issuer can validate it. The operating rule the book states bluntly: when in doubt, reverse — never assume an outcome.Evaluate retry safety. Only once the state is confirmed and reconciled do you decide whether a retry is even appropriate, and if it is, you reuse the same identifier.
One detail worth designing around: a reversal is fast at the message level but the customer-visible release lags. Scheme and issuer rules generally require the hold to be released within about 60 minutes of a matched reversal, so the protocol succeeded long before the cardholder sees their balance restored. Build the UX around that gap instead of promising an instant refund. The same timing nuance applies across reversals, refunds, and chargebacks, which sit at different points of the settlement lifecycle and are routinely confused.
There is also the late response: an approval that arrives after you have already reversed. The correct handling is to ignore it for the live decision, log it, and let reconciliation flag the mismatch — not to let a stale message reopen a closed transaction.
Convenience versus the ledger
There is a real pull toward the simple version. A loop that retries until it gets a 200 OK is less code than a status query, a reconciliation step, and a reversal path. The trade-off is not even close once you weigh the outcomes. An unnecessary support call from a customer whose payment timed out is minor friction. Charging that customer twice is a breach of trust and a reconciliation cleanup that costs far more than the code you saved.
This is also why offline and store-and-forward modes deserve extra caution: when authorization is deferred, the same uncertainty is stored up and replayed at reconnect, which is where unguarded retries quietly turn into duplicates. The mitigations are the same family — strict thresholds, auto-reversals on reconnect, reconciled batches. I covered that terrain in offline EMV and store-and-forward, and the full happy-path lifecycle in what actually happens in the 2–3 seconds of a card payment.
A single version of the truth
Payments get described as moving money from A to B. The mechanics of moving it are mostly solved. The hard part is maintaining one authoritative version of the truth across networks that drop packets, hang connections, and lose responses at the worst possible moment.
So the hardest problem in payments is not authorizing a transaction. It is knowing, for certain, whether you already did. When you audit your own flows, the question to ask is simple: does the system treat a network error as a failure to overwrite, or as an uncertain state to investigate first?
Key takeaways
- A double charge is usually a certainty problem, not a code problem. The error told you that you lost visibility, not that the payment failed.
- Generate the transaction reference at the moment of intent and persist it before the first send, so a retry can reuse it and the host can deduplicate.
- Retries before the customer commits are cheap; after the state machine enters
AUTH_REQUESTED, every error is an uncertain outcome. - Recover with read-before-write: query status, reconcile, reverse (
0400/0420) when in doubt, then decide on retry — reusing the same identifier. - Design for customer impact over implementation convenience. The cost of a duplicate charge dwarfs the cost of a redundant support call.
Further reading
- Reversals, Refunds, and Chargebacks: Decoding the Payment Lifecycle — where a reversal sits relative to settlement, and why it differs from a refund
- What Actually Happens in the 2–3 Seconds of a Card Payment — the full card-present authorization lifecycle
- Offline EMV vs. Store-and-Forward — deferred authorization and the duplicate risk it stores up
- ISO 8583 — financial transaction messaging, including reversal MTIs
0400/0420 - EMVCo, EMV Integrated Circuit Card Specifications, Book 3: Application Specification
- Point-of-Sale Systems Architecture: A Practical Guide to Secure, Certifiable POS Systems, Chapter 8 (The Transaction Lifecycle) — timeouts, idempotency patterns, reversal flows, and the recovery state machine