This is Part I of a two-part series on multi-agent AI architecture. This post covers centralized orchestration. Part II explores the opposite approach: swarm intelligence.
“Super agent” is mostly a vendor label. Underneath it sits a coordination pattern that single-model, turn-by-turn chat cannot run reliably: multi-step workflows with branching logic, delegated expertise, and external system integration.
I’ve been reading about super agents across AWS prescriptive guidance, IBM’s multi-agent research, LangGraph’s implementation docs, and a handful of practical engineering write-ups. The term is not standardized. Attention uses it for a revenue-execution product [1]. AWS describes a supervisor agent that delegates to specialists [2]. LangGraph documents the same shape as graph nodes with shared state [5]. What repeats across those sources is the architecture, not the branding: a goal-decomposing orchestrator, loosely coupled specialists, structured communication, and one authoritative state store.
Multi-agent coordination is not new. Wooldridge’s survey of the field traces decades of research on autonomous agents, message protocols, and shared environments [9]. LLMs made the pattern practically deployable in ways that were difficult three years ago. This post organizes what I took from that reading: what the pattern actually means, how agents communicate in production-shaped systems, and a minimal Python example I wrote to see the mechanics before reaching for a framework.
What is a super agent?
Confirmed: In current vendor and framework documentation, a “super agent” or supervisor agent is an orchestrator that interprets a high-level goal, decomposes it into sub-tasks, coordinates tools and specialist agents, and runs a multi-step workflow with bounded human intervention [1][2][5][6].
Interpretation: The useful distinction from a standard chatbot is behavioral, not magical. A chatbot responds turn-by-turn. A super agent plans, delegates, acts, and revises when intermediate results fail checks.
The capabilities that show up repeatedly:
- Goal decomposition — translate “audit our Q2 pipeline and notify the reps” into a sequenced set of executable tasks.
- Tool and sub-agent orchestration — coordinate search, code execution, external APIs, CRM writes, and domain-specific agents as one workflow.
- Long-horizon context — preserve user intent, project state, and intermediate results across multiple reasoning steps.
- External action — send email, update records, generate documents, book reservations; not just describe how.
- Human-in-the-loop gates — pause for confirmation, accept corrections, revise the plan.
Anthropic’s agent guidance makes the same point in engineering terms: multi-agent setups pay off when a single agent hits limits on specialization, parallel exploration, or open-ended task paths — but only when the orchestration layer is designed deliberately [8].
Do agents actually talk to each other?
Yes. In multi-agent systems, agents coordinate through structured messages: sharing intermediate results, announcing tasks, and negotiating ownership. The interesting part is not whether they communicate, but which mechanism you choose and what that choice costs at runtime.
Communication mechanisms
Three mechanisms dominate current LLM agent stacks.
Message passing. Agents exchange typed messages — request, result, status, feedback — over a bus, queue, or shared memory store. Payloads carry sender, receiver, intent, content, and timestamp so both sides can route and act reliably. AWS maps this layer to SQS, EventBridge, or similar services in production deployments [2]. This is the most flexible option and the one that most closely resembles traditional distributed systems communication.
Shared state. Instead of direct peer calls, agents read from and write to a single authoritative state object. LangGraph formalizes this as graph nodes that receive state and return updates [5]. Agents do not need to know about each other — only about the state contract. The state object is both channel and coordination mechanism.
Natural language inside a structured envelope. LLM agents can exchange plain-text prompts, but production systems wrap them in JSON schemas or small DSLs to reduce ambiguity and enable deterministic parsing. The envelope carries routing and type information; the natural language carries semantic content.
FIPA’s agent-communication-language work predates the LLM wave and remains a useful reference for why typed performatives matter when machines coordinate [10].
Coordination patterns
The patterns I kept seeing include request–response, broadcast, task announcement with bidding, and peer refinement loops where one agent critiques another’s output. The coordination role is either explicit — a planner delegates to workers — or implicit — outputs flow through defined contracts in a collaborative graph.
The architectural trade-off is concrete. A centralized planner is easier to reason about and debug, but it concentrates failure at one node. A fully distributed collaboration graph is more resilient but harder to monitor. VentureBeat’s May 2025 piece on multi-agent orchestration frames this as a choice between hierarchical control and federated coordination [7]. Production systems I have looked at usually land in the middle: a planner that delegates to autonomous specialists, with guardrails and fallback logic at the orchestration layer.
A minimal in-process pattern
To make the idea concrete, I wrote a minimal example with three pieces: a shared state object, two agent functions, and a lightweight orchestrator that sequences them.
from dataclasses import dataclass, field
from typing import List, Dict
@dataclass
class State:
user_goal: str
messages: List[Dict[str, str]] = field(default_factory=list)
draft: str = ""
review: str = ""
def writer_agent(state: State) -> None:
state.draft = f"Draft for goal: {state.user_goal}"
state.messages.append({
"from": "writer",
"to": "reviewer",
"type": "draft",
"content": state.draft,
})
def reviewer_agent(state: State) -> None:
incoming = state.messages[-1]["content"]
state.review = f"Reviewed version of: {incoming}"
state.messages.append({
"from": "reviewer",
"to": "writer",
"type": "review",
"content": state.review,
})
def run_workflow(goal: str) -> State:
state = State(user_goal=goal)
writer_agent(state)
reviewer_agent(state)
return state
state = run_workflow("Create a short API integration summary")
print(state.messages)
print(state.review)
writer_agent() produces a draft and appends a typed message targeted at the reviewer. reviewer_agent() reads that message and writes its response back into the same structure. Both agents run in one process, but the message list enforces a protocol boundary. That separation is what makes the design debuggable and extensible.
Why this pattern scales
The agents stay loosely coupled: they do not call each other’s business logic directly. They communicate through state and message contracts. That makes it straightforward to insert a supervisor, add retries, inject validation, or introduce checkpointing without rewriting each agent’s core job.
LangGraph expresses the same idea as graph nodes that receive state and can return a Command combining state updates with routing to the next node [5]. The plain Python example maps to START → writer → reviewer → END, with shared state as the communication channel. Building the minimal version first helped me see what the framework is abstracting.
The super agent as orchestrator
In production multi-agent systems, the super agent is usually the orchestrator. That role distinction matters.
The orchestrator does not perform domain work itself. It decomposes the user goal and assigns sub-tasks to specialist agents. It tracks workflow state, evaluates intermediate results, and decides on next steps, retries, or fallbacks. It enforces policies, cost boundaries, and safety checks at one control point. Every specialist agent keeps a scoped responsibility. The orchestrator keeps workflow-level visibility.
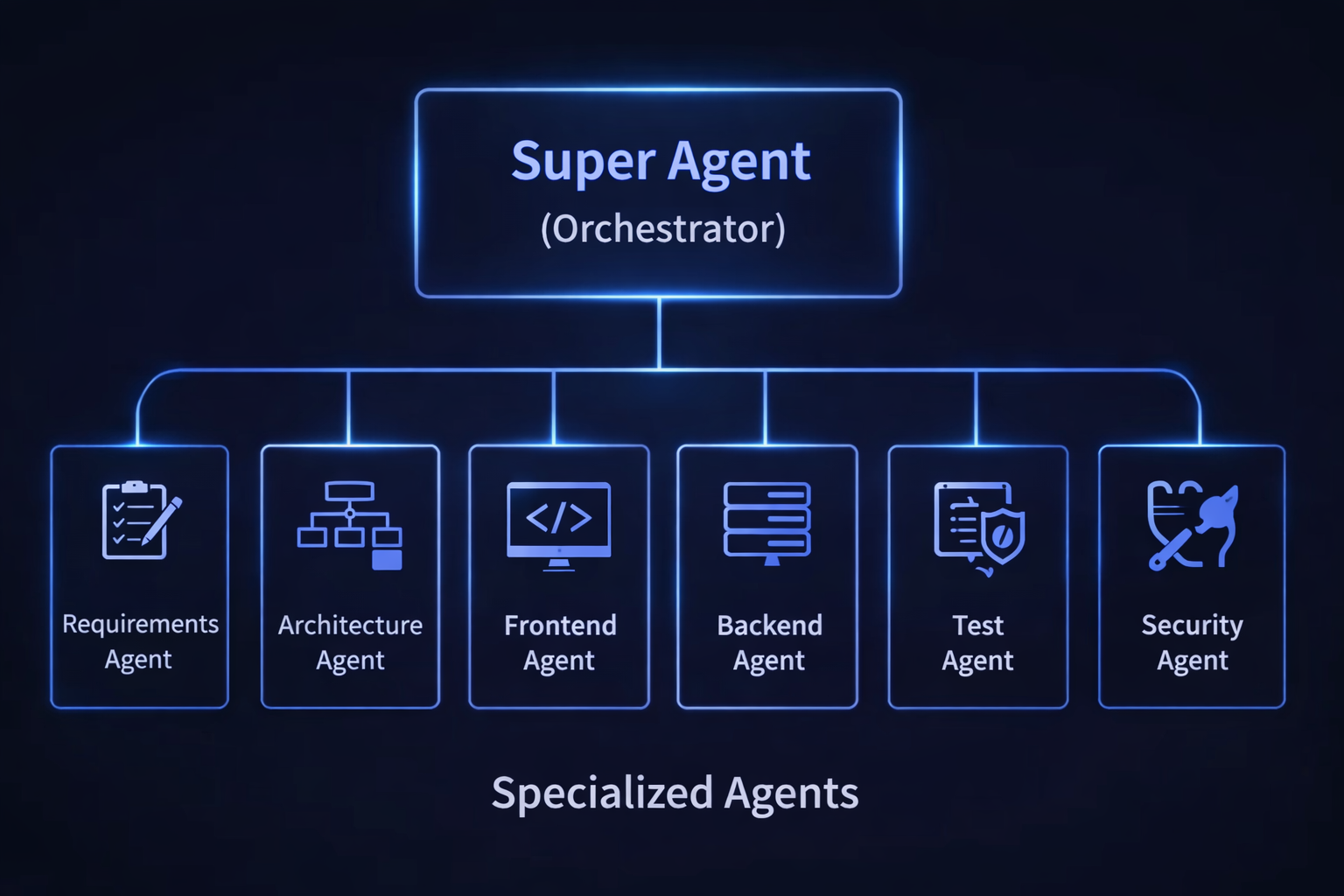
The diagram at the top of this post is the pattern in one picture: one orchestrator delegates to Requirements, Architecture, Frontend, Backend, Test, and Security agents. Each owns a scoped role. None depends directly on the others. Adding specialists changes the assignment table, not the orchestration contract.
What stays constant: the orchestrator is the only node with full workflow visibility. Specialist agents receive scoped inputs and produce scoped outputs. They do not need to know what the other agents are doing. The coordination burden sits with the orchestrator.
The three-layer production pattern that kept surfacing:
| Layer | Role |
|---|---|
| Orchestrator / super agent | Owns the workflow graph, task assignment, and gate logic |
| Shared context store | Versioned state or artifacts (DB, files, or structured in-memory state) — single source of truth |
| Specialist agents | Read from the store, write outputs into it, never assume hidden state |
This mirrors how well-designed distributed systems already work: a coordinator with global visibility, workers with local scope, and a shared data layer that keeps everyone aligned on the same facts.
Single source of truth: non-negotiable
Multi-agent systems fail when each agent builds its own version of reality. Mature architectures anchor the workflow to one authoritative store — shared in-process state, a central database, or a versioned artifact store [2][5][7].
The benefits match what I have seen in distributed systems generally:
Consistency. Parallel agents do not drift into separate world-views. When a coder agent writes a function and a test agent writes assertions, both work from the same artifact, not separate memories of the specification.
Debuggability. One place inspects current state across the workflow. When something breaks — and in multi-agent systems something eventually does — you need a single pane to see what each agent read, what it produced, and where the chain failed.
Clean handoffs. Agents know which fields or artifacts they own. They read, process, and write through the central store instead of carrying local assumptions forward.
Agents may keep local working memory for their own reasoning steps, but they reconcile through the central truth store before producing outputs that other agents depend on. Without that reconciliation step, the system works until internal models diverge. They eventually will.
The bigger picture
The super agent label is marketing noise if you treat it as a product category. As an architecture, it is concrete: a goal-decomposing orchestrator, loosely coupled specialists, structured inter-agent communication, and one authoritative state store. The Python example above is deliberately minimal. I wanted the essential mechanics visible before layering on a framework.
If you are building toward LangGraph or a similar stack, the mapping is direct: nodes are agents, edges are message contracts, graph state is your single source of truth. The abstraction changes. The architecture does not.
The hard problem in agentic AI is reliable coordination across multiple agents. That is a systems engineering problem: clear contracts, shared state, scoped responsibility, centralized coordination where auditability matters. Model capability handles local reasoning. Architecture handles reliability at workflow scale.
Centralized orchestration is not the only coordination model. Part II of this series explores the opposite bet: swarm intelligence, where coordination is decentralized and global competence emerges from local interactions rather than a top-down plan. Knowing when each pattern wins is what separates a workable multi-agent design from an overengineered one.
References
- Attention. “Introducing Super Agent: Your AI Teammate for Revenue Execution.” 2025. attention.com
- AWS Prescriptive Guidance. “Multi-agent collaboration.” docs.aws.amazon.com
- IBM Think. “What is a Multi-Agent System.” ibm.com
- DigitalOcean. “Agent Communication Protocols Explained.” digitalocean.com
- LangChain. “LangGraph Multi-Agent Systems Overview.” langchain-ai.github.io
- LangChain. “Multi-Agent Collaboration Tutorial.” langchain-ai.github.io
- VentureBeat. “Beyond single-model AI: How architectural design drives reliable multi-agent orchestration.” May 2025. venturebeat.com
- Anthropic. “Building Effective AI Agents: Architecture Patterns and Implementation Frameworks.” resources.anthropic.com
- Wooldridge, M. An Introduction to MultiAgent Systems. 2nd ed. Wiley, 2009.
- Foundation for Intelligent Physical Agents (FIPA). “FIPA Agent Communication Language Specifications.” fipa.org
- Part II: Swarm Intelligence — The Opposite Architectural Bet (forthcoming) — decentralized coordination, emergent behavior, and when to choose swarm over orchestrator
- AI Sycophancy — why confident-looking AI output still requires verification, even from autonomous agents
- Reasoning Models and Deep Reasoning in LLMs — the reasoning strategies that power individual agents
- The Obsolescence Paradox: Why the Best Engineers Will Thrive in the AI Era — engineering judgment in the age of autonomous AI systems