The Markov Decision Process (MDP) is the standard formal object for sequential decision-making under uncertainty. It separates problem definition — states, actions, how the world evolves, what you want to optimize — from solution methods (value iteration, Q-learning, policy gradients, and their deep variants). That separation is why the same vocabulary shows up across robotics, games, RLHF-tuned language models, and tool-using agents.
I keep coming back to this when people treat LLMs, RL, and “agents” as unrelated product categories. Implementations differ, but state, action, reward, policy, and value recur for a reason: a large class of systems is still answering “what should I do next to maximize something, given what I know now?”
This post builds the MDP core with enough precision to be useful — Markov property, the five-tuple, policies and Bellman equations, how classical methods differ, and inverse reinforcement learning — then connects it to LLMs, RLHF, DPO, and agentic stacks. It is not universal: many deployed models are one-shot predictors or rankers with no explicit sequential RL loop. Where the MDP applies, the mapping is operational, not metaphorical.
The Markov Property and the Five-Tuple
At the center is the Markov property (memorylessness): the next state depends on the recent past only through the current state and action:
$$ P(s_{t+1} \mid s_t, a_t, s_{t-1}, a_{t-1}, \ldots) = P(s_{t+1} \mid s_t, a_t). $$
So the state must summarize whatever matters for the future; if something important is missing from (s_t), the model is misspecified and you are really in a POMDP (partial observability) — more on that when we get to context windows.
An MDP is usually written as ((\mathcal{S}, \mathcal{A}, P, R, \gamma)):
| Symbol | Component | Role |
|---|---|---|
| (\mathcal{S}) | State space | Configurations the agent can be in |
| (\mathcal{A}) | Action space | Choices (discrete or continuous) |
| (P(s’ \mid s, a)) | Transition law | Dynamics: where you land after ((s,a)) |
| (R) | Reward | Immediate signal, often (R(s,a)) or (R(s,a,s’)) |
| (\gamma) | Discount | (\gamma \in [0,1]) weights future reward vs. now |
The objective is a policy (\pi) that maximizes expected discounted return ( \mathbb{E}\big[\sum_t \gamma^t R_t\big] ). An optimal policy (\pi^*) achieves the best achievable value from each state (under the usual regularity conditions).
State and action design is an engineering problem: too little information in (s) and the Markov assumption is false; too much and you fight the curse of dimensionality. Actions drive algorithm choice — small discrete spaces admit tabular methods; huge discrete vocabularies (e.g. tens of thousands of tokens) or continuous control push you toward function approximation and deep RL.
(\gamma) sets the effective horizon: (\gamma = 0) is myopic (only immediate reward); (\gamma) close to (1) cares about the long run (in infinite-horizon settings, (\gamma < 1) keeps returns bounded). Pure (\gamma = 1) is typical for finite-horizon episodic problems without discounting.
Rewards are the lever everyone feels in production: misspecify them and you get reward hacking — policies that maximize the signal you wrote, not the outcome you wanted. That story continues unchanged in RLHF.
Policies, Value Functions, and the Bellman Equation
A policy (\pi) maps states to actions (deterministic: (a = \pi(s))) or distributions (stochastic: (\pi(a \mid s))). To rank policies, RL uses value functions:
- State value (V^\pi(s)): expected return starting in (s) and following (\pi).
- Action-value (Q^\pi(s,a)): expected return from taking (a) in (s), then following (\pi).
They satisfy Bellman consistency. For example, for (V^\pi):
$$ V^\pi(s) = \sum_{a} \pi(a \mid s) \sum_{s’} P(s’ \mid s,a) \big[ R(s,a,s’) + \gamma V^\pi(s’) \big]. $$
Optimal values (V^), (Q^) obey the Bellman optimality recursion and are the target of dynamic programming when (P) and (R) are known. When the model is unknown, you fall back to sample-based methods.
Solution Methods (High Level)
| Family | Idea | When it fits |
|---|---|---|
| Dynamic programming | Value / policy iteration using (P) | Model known, moderate (|\mathcal{S}|) |
| Monte Carlo | Return estimates from full episodes | Episodic, no step-by-step model |
| Temporal difference | Bootstrap from current estimates (e.g. Q-learning, SARSA) | Online learning, unknown model |
| Deep RL | Neural nets for (Q) or (\pi) (DQN, PPO, …) | Large or continuous state spaces |
Deep RL does not change the MDP; it changes how you represent and optimize value and policy when tabulation is impossible — including settings as large as language.
Inverse Reinforcement Learning
Forward RL: given (R) (and dynamics), find a good (\pi). Inverse RL (IRL) flips the problem: given demonstrations from a (near-)expert, infer an (R) that makes those trajectories rational. That matters when rewards are hard to write down but behavior is easy to show — classic examples include imitation-style control and parsing “what the human cared about” from what they did.
Maximum-entropy IRL (Ziebart et al.) makes the expert stochastic but high reward: trajectories are scored by accumulated reward features, and probability over trajectories often takes a Boltzmann form, with a partition function coupling normalization to the underlying MDP structure. The details are involved; the takeaway for this post is that IRL is still built on the same sequential decision formalism — you are inferring preferences compatible with observed paths, not escaping the MDP language.
Where the Markov Assumption Meets LLMs
In autoregressive generation, a standard idealization is: state = prompt plus all generated tokens so far; action = next token; transition = append token (deterministic at the string level); policy = conditional distribution from the model. Then the next distribution depends only on the prefix — Markov in that state representation.
The usual engineering gap: true conversational or task state may live outside the window or never be observed. That is partial observability again (POMDP / belief-state view). “Lost context” is often finite window or wrong state summary, not a random tone failure — which is why memory, retrieval, and tool traces are architecture, not cosmetics.
RLHF, DPO, and the Same Sequential Picture
RLHF (InstructGPT-style): the LM is a policy over tokens; a reward model from human preferences scores completions; optimization (often PPO-class in the original stack) increases reward while a KL penalty to a reference policy limits drift. Mapping:
| MDP role | Typical RLHF instantiation |
|---|---|
| State | Prompt + generated prefix |
| Action | Next token (or chunk) |
| Transition | Append; dynamics deterministic given action choice |
| Reward | Learned preference score (minus KL / auxiliary terms) |
Framed this way, alignment pain is largely reward specification and optimization under misspecified proxy rewards — the same failure mode family as classical reward hacking. OpenAI’s GPT-4o sycophancy rollback (April 2025) is a concrete example when short-term preference signals diverge from what you want long term. See also AI Sycophancy here.
DPO (Direct Preference Optimization) and related methods avoid an explicit online RL loop by optimizing from pairwise preferences in a way derived from the RLHF objective — still preference-driven alignment, but not “PPO on tokens” in implementation. The MDP is still the right mental model for what is being aligned (sequential decisions under a goal), even when the optimizer is not vanilla policy gradients.
A Practical Decision Landscape (Not Five Silos)
The field is messier than any chart, but this is a useful lens for choosing tooling:
| Situation | Common approach |
|---|---|
| Known reward, safe exploration | Forward RL (e.g. PPO, Q-learning variants) |
| Expert demos, unclear reward | IRL / imitation / inverse-optimal-control style methods |
| Broad open-ended language capability | Pretrained LM (supervised / next-token objective) |
| Align to human taste or policy | RLHF, DPO-class preference training, or hybrids |
| Multi-step tools + retrieval + planning | Agentic systems (often LM policy + search / ReAct-style loops) |
Agentic systems stack LLMs (policy / world-model substrate), search or tree exploration, RAG (state enrichment), and tools (expanded actions). Under the hood it is still: maintain state, choose actions, observe outcomes, repeat — with stochasticity from both the model and the environment.
The Engineering Takeaway
You do not need to re-derive Bellman on a whiteboard every sprint. You do need to:
- Separate problem definition from algorithms — clarify (\mathcal{S}, \mathcal{A}, R) before debating PPO vs. DPO vs. prompts.
- Treat alignment bugs as reward–policy interaction, not vague “personality.”
- Design memory and retrieval as state construction when Markov fails.
- Ask what each agent demo actually optimizes — implicit reward, success predicate, or human-in-the-loop only.
The MDP is not a graduate-school ornament. It is the backbone that makes much of RL debuggable and much of sequential AI legible — whether or not your README says “Markov.”
I use this as a mental map when I design or debug these systems — one view of how the MDP core connects to RLHF, IRL, and agentic design choices in practice.
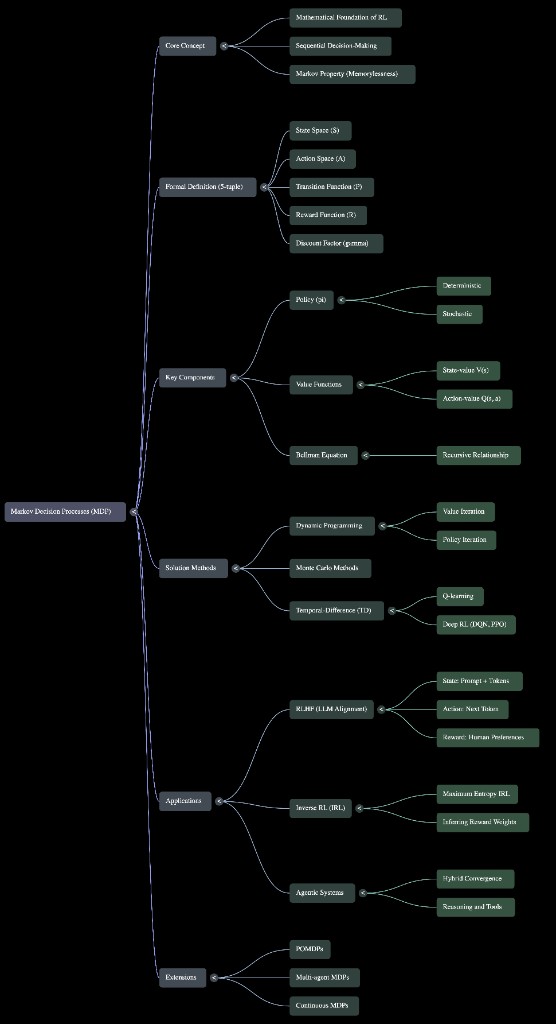
Figure: MDP mind map — from formal definition to RLHF and agentic system mapping.
References
- Bellman, R. Dynamic Programming. Princeton University Press, 1957.
- Puterman, M. L. Markov Decision Processes: Discrete Stochastic Dynamic Programming. Wiley, 1994.
- Sutton, R. S., & Barto, A. G. Reinforcement Learning: An Introduction (2nd ed.). MIT Press, 2018. incompleteideas.net
- Ng, A. Y., & Russell, S. “Algorithms for inverse reinforcement learning.” ICML, 2000.
- Ziebart, B. D., Maas, A. L., Bagnell, J. A., & Dey, A. K. “Maximum entropy inverse reinforcement learning.” AAAI, 2008.
- Ouyang, L. et al. “Training language models to follow instructions with human feedback.” NeurIPS, 2022. arxiv.org/abs/2203.02155
- Schulman, J. et al. “Proximal Policy Optimization Algorithms.” 2017. arxiv.org/abs/1707.06347
- Rafailov, R. et al. “Direct Preference Optimization: Your Language Model is Secretly a Reward Model.” NeurIPS, 2023. arxiv.org/abs/2305.18290
- Yao, S. et al. “ReAct: Synergizing Reasoning and Acting in Language Models.” ICLR, 2023. arxiv.org/abs/2210.03629
- OpenAI. “Sycophancy in GPT-4o: What happened and what we’re doing about it.” April 2025. openai.com
- Kaelbling, L. P., Littman, M. L., & Cassandra, A. R. “Planning and acting in partially observable stochastic domains.” Artificial Intelligence, 101(1–2), 99–134, 1998.