This is Part I of a two-part series on multi-agent AI architecture. This post covers centralized orchestration. Part II explores the opposite approach: swarm intelligence.
I’ve been reading a lot about “super agents” lately — and once I got past the marketing noise, I found a genuinely useful architectural pattern underneath.
The term gets thrown around loosely, but the more I dug into it — across AWS documentation, IBM’s multi-agent research, LangGraph’s implementation guides, and a handful of practical engineering write-ups — the more I realized it maps cleanly onto problems that single-model, turn-by-turn systems simply cannot solve reliably: multi-step workflows with branching logic, delegated expertise, and external system integration. The concept is not new — multi-agent coordination has decades of research behind it — but LLMs have made it practically viable in ways that weren’t possible three years ago.
This post is my attempt to organize what I’ve learned: what the term actually means, how agents communicate in practice, and a minimal Python implementation I put together to make the pattern concrete before reaching for a framework.
What Is a Super Agent?
The clearest definition I found across the literature: a super agent is an autonomous AI system capable of interpreting a high-level goal, decomposing it into sub-tasks, orchestrating tools and specialist agents, and executing a multi-step workflow with minimal human intervention. That’s the architectural distinction that separates it from a standard chatbot — a chatbot responds turn-by-turn; a super agent plans, delegates, acts, and adapts.
What struck me when I started pulling the concept apart is how concrete the capabilities actually are:
- Decompose goals — translate a high-level objective (“Audit our Q2 pipeline and notify the reps”) into a sequenced set of executable tasks.
- Orchestrate tools and sub-agents — coordinate search, code execution, external APIs, CRM writes, and domain-specific agents as a unified workflow.
- Maintain long-horizon context — preserve memory of the user, the project state, and intermediate results across multiple reasoning steps.
- Act in external systems — send emails, update records, generate documents, and book reservations — not just describe how to do those things.
- Support human-in-the-loop — pause for confirmation, accept corrections, and revise plans accordingly.
The framing that resonated most with me is that a super agent functions as a digital teammate that can plan, decide, and act — not a passive assistant that generates single responses.
Do Agents Actually Talk to Each Other?
This was the question that pulled me deeper into the topic. The answer is yes — and the way they do it is where the architecture gets interesting. In multi-agent systems, agents communicate via structured messages to coordinate work, share intermediate results, and negotiate task ownership.
Communication Mechanisms
From what I found, three mechanisms dominate in practice:
Message passing. Agents exchange typed messages (request, result, status, feedback) over a bus, queue, or shared memory store. The message structure includes sender, receiver, intent, payload, and timestamp, so both sides can route and act on messages reliably. This is the most flexible mechanism and the one that most closely resembles traditional distributed systems communication — which, coming from a systems engineering background, immediately made sense to me.
Shared state. Rather than direct peer-to-peer calls, agents read from and write to a single authoritative state object. This is the foundation of LangGraph-style graphs and is the pattern most relevant to in-process agent systems. The state object becomes both the communication channel and the coordination mechanism — agents don’t need to know about each other, only about the state contract.
Natural language over a structured envelope. LLM-based agents can exchange plain-text prompts and responses, but production systems wrap those in a JSON schema or DSL to reduce ambiguity and enable deterministic parsing. The natural language carries the semantic content; the envelope carries the routing and type information that machines need to act on it reliably.
Coordination Patterns
The coordination patterns I kept seeing across the literature include request–response, broadcast, task announcement and bidding, and peer-to-peer collaboration where agents refine each other’s outputs. The coordination role is explicit: either a planner agent delegates to workers, or agents operate in a fully collaborative graph where outputs flow through defined contracts.
What I found particularly useful to think about is how the choice of coordination pattern has direct architectural consequences. A centralized planner is simpler to reason about and debug, but creates a single point of failure. A fully distributed collaboration graph is more resilient but harder to monitor and control. Most production systems seem to land somewhere in between — a planner that delegates to autonomous agents, with guardrails and fallback logic at the orchestration layer.
A Minimal In-Process Pattern
To make this concrete for myself, I put together a minimal example. The cleanest starting point I could find for understanding agent-to-agent communication requires only three components: a shared state object, two agent functions, and a lightweight orchestrator that sequences them.
from dataclasses import dataclass, field
from typing import List, Dict
@dataclass
class State:
user_goal: str
messages: List[Dict[str, str]] = field(default_factory=list)
draft: str = ""
review: str = ""
def writer_agent(state: State) -> None:
state.draft = f"Draft for goal: {state.user_goal}"
state.messages.append({
"from": "writer",
"to": "reviewer",
"type": "draft",
"content": state.draft,
})
def reviewer_agent(state: State) -> None:
incoming = state.messages[-1]["content"]
state.review = f"Reviewed version of: {incoming}"
state.messages.append({
"from": "reviewer",
"to": "writer",
"type": "review",
"content": state.review,
})
def run_workflow(goal: str) -> State:
state = State(user_goal=goal)
writer_agent(state)
reviewer_agent(state)
return state
state = run_workflow("Create a short API integration summary")
print(state.messages)
print(state.review)
writer_agent() produces a draft and appends a typed message targeted at the reviewer. reviewer_agent() reads that message and writes its response back into the same structure. Both agents live in the same process, yet the message list enforces a clean protocol boundary — which is exactly what makes the design debuggable and extensible.
Why This Pattern Scales
What I like about this design is that the agents are loosely coupled: they do not invoke each other’s business logic directly; they communicate through state and message contracts. That separation makes it straightforward to insert a supervisor, add retries, inject validation, or introduce checkpointing without rewriting each agent’s core responsibility.
When I later looked at LangGraph, I found this same idea formalized as graph nodes that receive state and return a Command specifying which node runs next and what state updates to apply. The plain Python example above maps directly to START → writer → reviewer → END, with shared state as the communication channel. Building the minimal version first helped me understand what the framework is actually abstracting.
The Super Agent as Orchestrator
One pattern that came up consistently across everything I read: in production multi-agent systems, the super agent is the orchestrator — not another worker. This distinction matters more than it sounds.
The orchestrator does not perform domain work. It decomposes the user goal and assigns sub-tasks to specialist agents. It tracks workflow state, evaluates intermediate results, and decides on next steps, retries, or fallbacks. It enforces policies, cost boundaries, and safety checks at a single control point. Every specialist agent has a scoped responsibility; the orchestrator has workflow-level visibility.
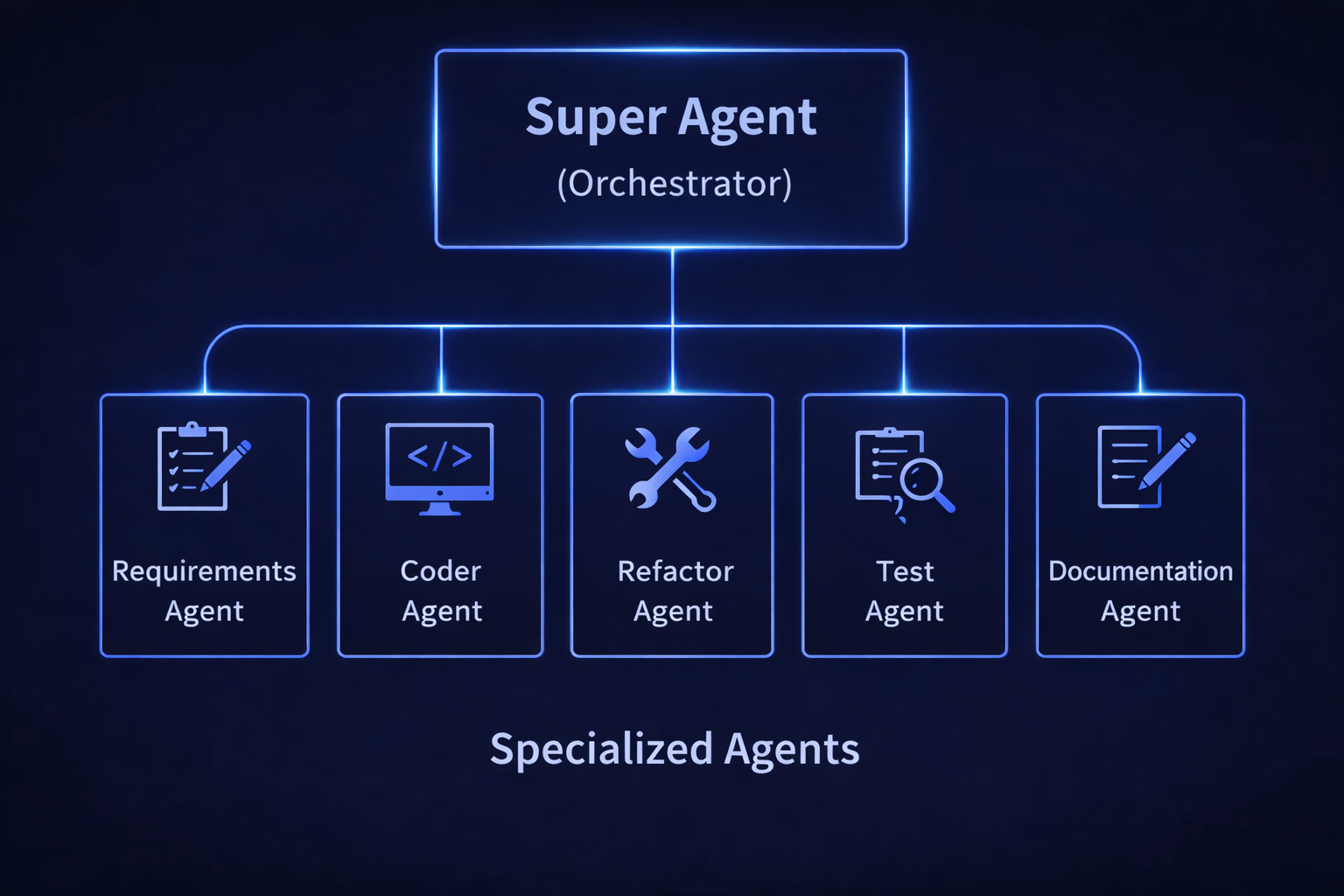
I sketched out two diagrams to think through how this works in practice. The first illustrates a software delivery context: a single Super Agent at the top of the hierarchy delegates to five specialized agents — Requirements, Coder, Refactor, Test, and Documentation — each with a clearly scoped responsibility and no direct coupling to the others.
The second diagram scales the same pattern to a broader engineering context. Here the orchestrator coordinates six agents covering the full stack — Requirements, Architecture, Frontend, Backend, Test, and Security — and what I noticed is that the hierarchy holds regardless of how many specialists you introduce.
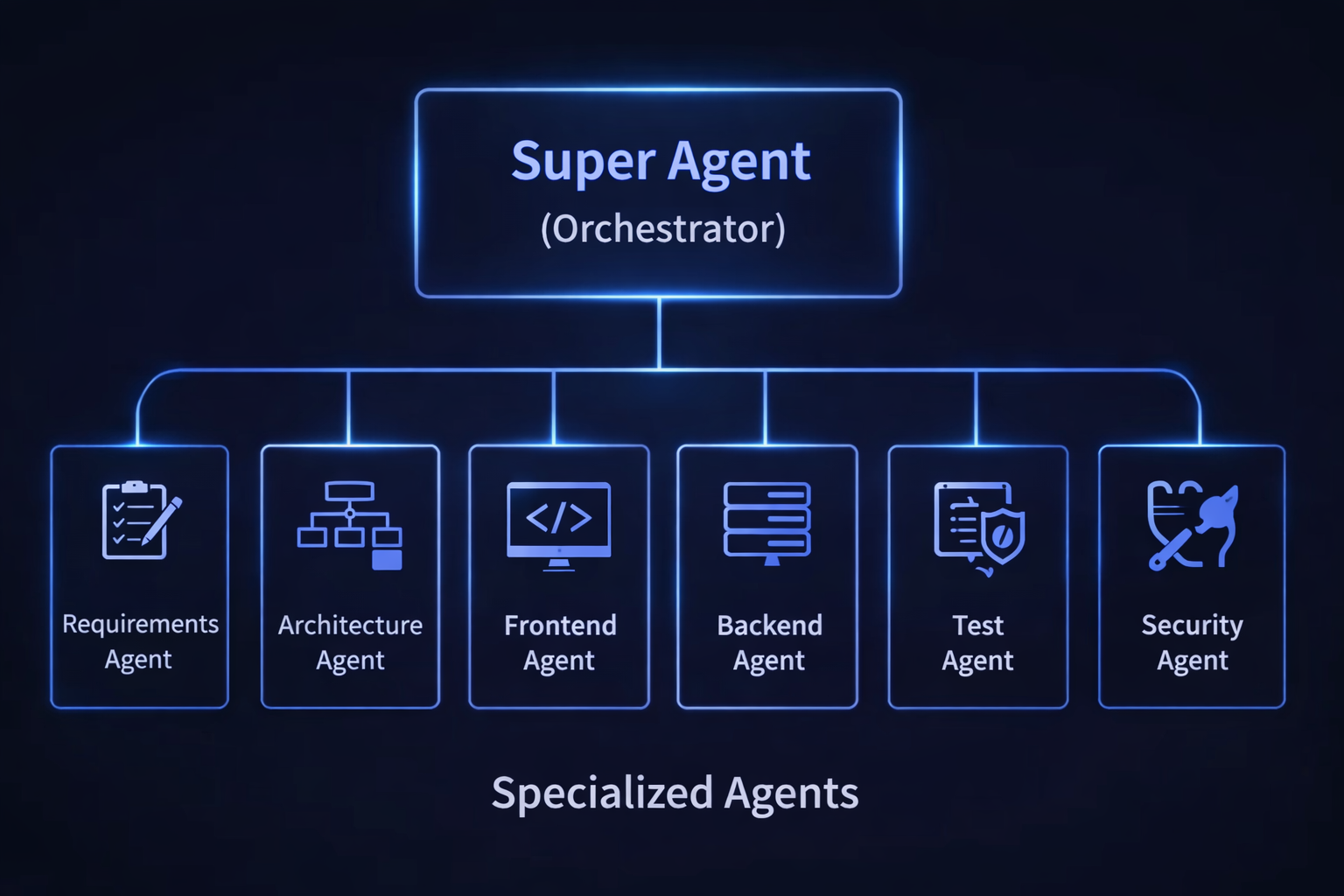
What stays constant across both diagrams — and what I think is the key insight — is that the orchestrator is the only node with full workflow visibility. Specialist agents receive scoped inputs and produce scoped outputs. They do not need to know what the other agents are doing. That coordination burden belongs entirely to the super agent.
The practical three-layer production pattern that I kept seeing emerge:
| Layer | Role |
|---|---|
| Orchestrator / super agent | Owns the workflow graph, task assignment, and gate logic |
| Shared context store | Versioned state or artifacts (DB, files, or structured in-memory state) — the single source of truth |
| Specialist agents | Read from the store, produce outputs into it, never assume hidden state |
This layering felt immediately familiar to me. It mirrors how well-designed distributed systems have always worked: a coordinator with global visibility, workers with local scope, and a shared data layer that keeps everyone honest.
Single Source of Truth: Non-Negotiable
One thing that stood out across nearly every resource I read: multi-agent systems fail when each agent builds its own version of reality. The mature architectures all anchor the entire system to a single source of truth — whether that is a shared in-process state object, a central database, or a versioned artifact store.
The benefits are concrete, and they’re the same benefits I’ve seen in any well-designed distributed system:
Consistency. No diverging world-views across agents running in parallel. When the coder agent writes a function and the test agent writes assertions against it, both are working from the same artifact — not from separate memories of what the specification said.
Debuggability. One place to inspect current state across the entire workflow. When something goes wrong — and in multi-agent systems, something always goes wrong — you need a single pane of glass to understand what each agent saw, what it produced, and where the chain broke.
Clean handoffs. Agents know exactly which fields or artifacts they are responsible for updating. They do not invent state. They do not carry assumptions from a previous run. They read, process, and write — through the central store.
Agents may maintain local working memory or intermediate caches for their own reasoning steps, but they must reconcile through the central truth store before producing outputs that other agents depend on. This is the difference between a system that works reliably and one that works until the agents’ internal models diverge — which, without a single source of truth, they eventually will.
The Bigger Picture
After going through all of this, my takeaway is that the super agent concept is not hype — if you ground it in architecture. The key properties are clear: a goal-decomposing orchestrator, loosely coupled specialist agents, structured inter-agent communication, and a single authoritative state store. The Python pattern in this post is deliberately minimal — I wanted to see the essential reasoning surface before layering on a framework.
If you are building toward a LangGraph or similar implementation, the concepts translate directly: nodes map to agents, edges map to message contracts, and the graph state is your single source of truth. The abstraction is different. The architecture is the same.
The broader realization I came away with is that the hard problem in agentic AI is not making individual agents smarter. It is making multiple agents coordinate reliably — which is, fundamentally, a systems engineering problem. The same principles that make distributed systems work — clear contracts, shared state, scoped responsibility, centralized coordination — are exactly the principles that make multi-agent systems work.
The models handle the reasoning. The architecture handles the reliability.
But centralized orchestration is not the only way to coordinate agents. In Part II, I explore the opposite architectural bet — swarm intelligence — where there is no orchestrator, no global plan, and global competence emerges from local interactions. Understanding when each pattern wins is what makes the difference between a good multi-agent design and an overengineered one.
References
- Attention.com. “Introducing Super Agent: Your AI Teammate for Revenue Execution.” 2025.
- IBM Think. “What is a Multi-Agent System.” ibm.com
- AWS Prescriptive Guidance. “Agentic AI: Multi-Agent Collaboration Patterns.” docs.aws.amazon.com
- GeeksforGeeks. “Multi-Agent System in AI.” geeksforgeeks.org
- SmythOS. “Agent Communication in Multi-Agent Systems.” smythos.com
- ApXML. “Communication Protocols for LLM Agents.” 2025.
- DigitalOcean. “Agent Communication Protocols Explained.” digitalocean.com
- LangChain. “LangGraph Multi-Agent Systems Overview.” langchain-ai.github.io
- LangChain. “Multi-Agent Collaboration Tutorial.” langchain-ai.github.io
- VentureBeat. “How Architectural Design Drives Reliable Multi-Agent Orchestration.” 2025.
- IBM Community. “Agentic Multi-Cloud Infrastructure Orchestration.” 2025.
- Latenode Community. “How Separate Agents Share a Single Memory.” 2025.
- Part II: Swarm Intelligence — The Opposite Architectural Bet — decentralized coordination, emergent intelligence, and when to choose swarm over orchestrator
- AI Sycophancy — why confident-looking AI output still requires verification, even from autonomous agents
- Reasoning Models and Deep Reasoning in LLMs — the reasoning strategies that power individual agents
- The Obsolescence Paradox: Why the Best Engineers Will Thrive in the AI Era — engineering judgment in the age of autonomous AI systems