9 min read
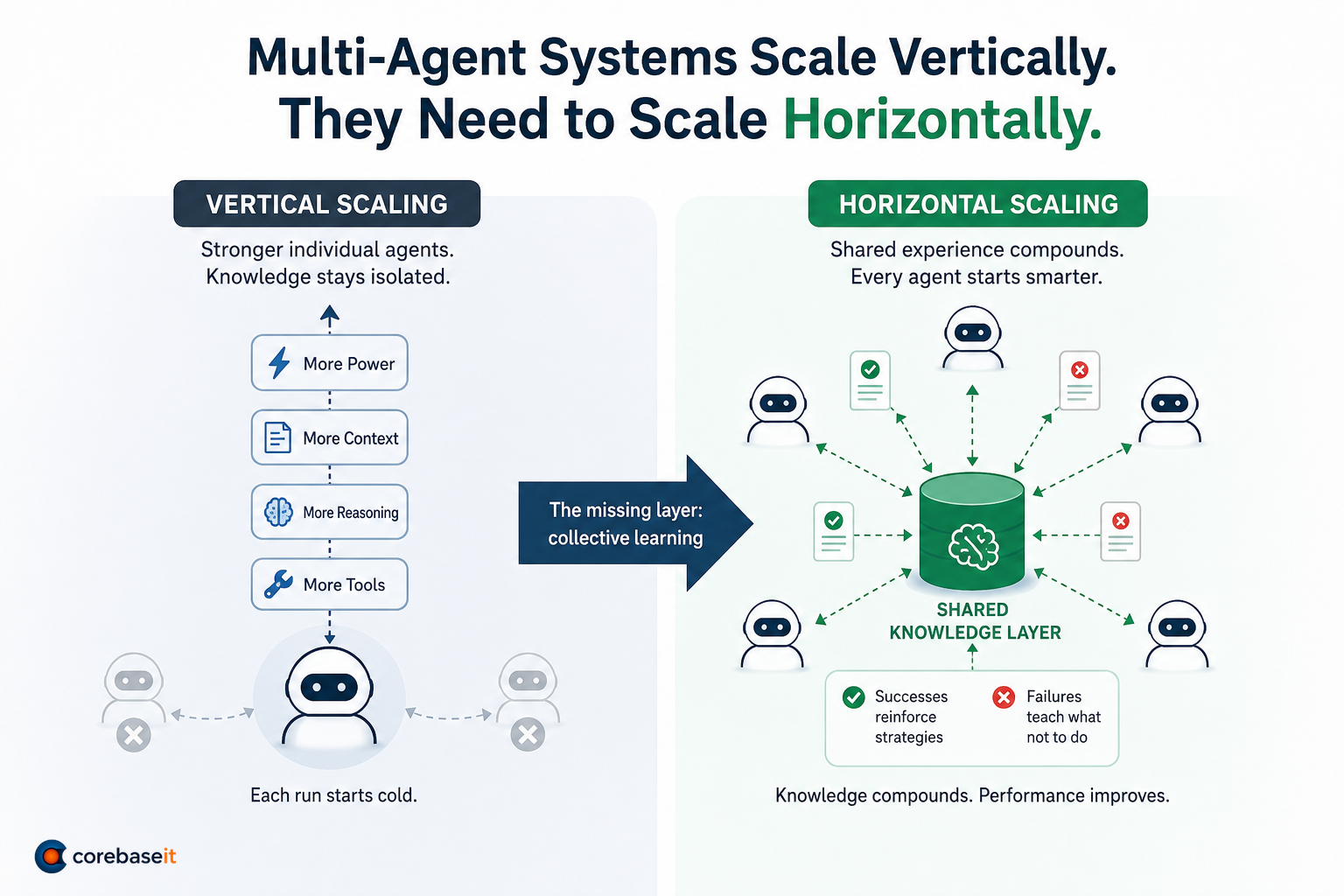
Multi-Agent Systems Scale Vertically. They Need to Scale Horizontally.
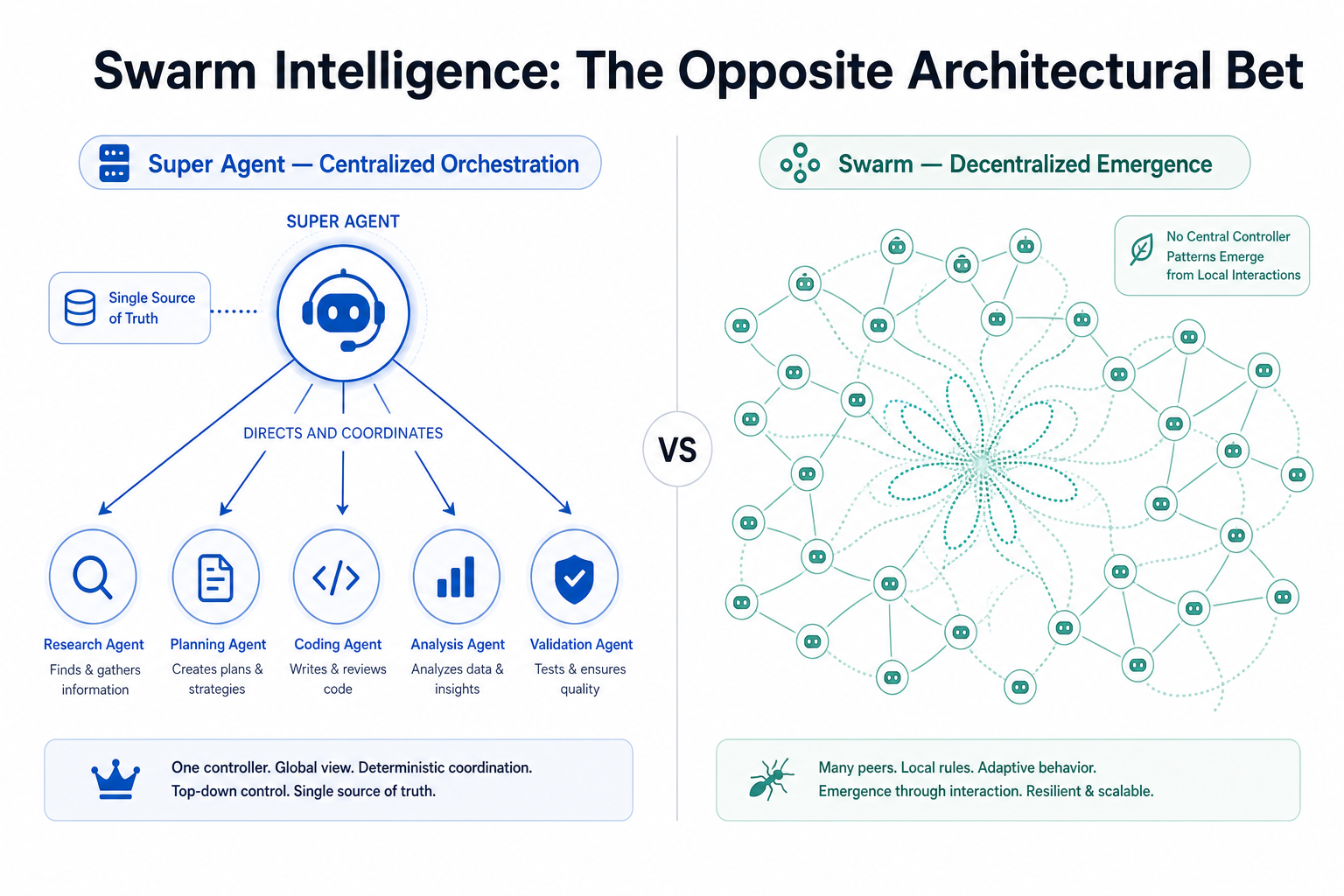
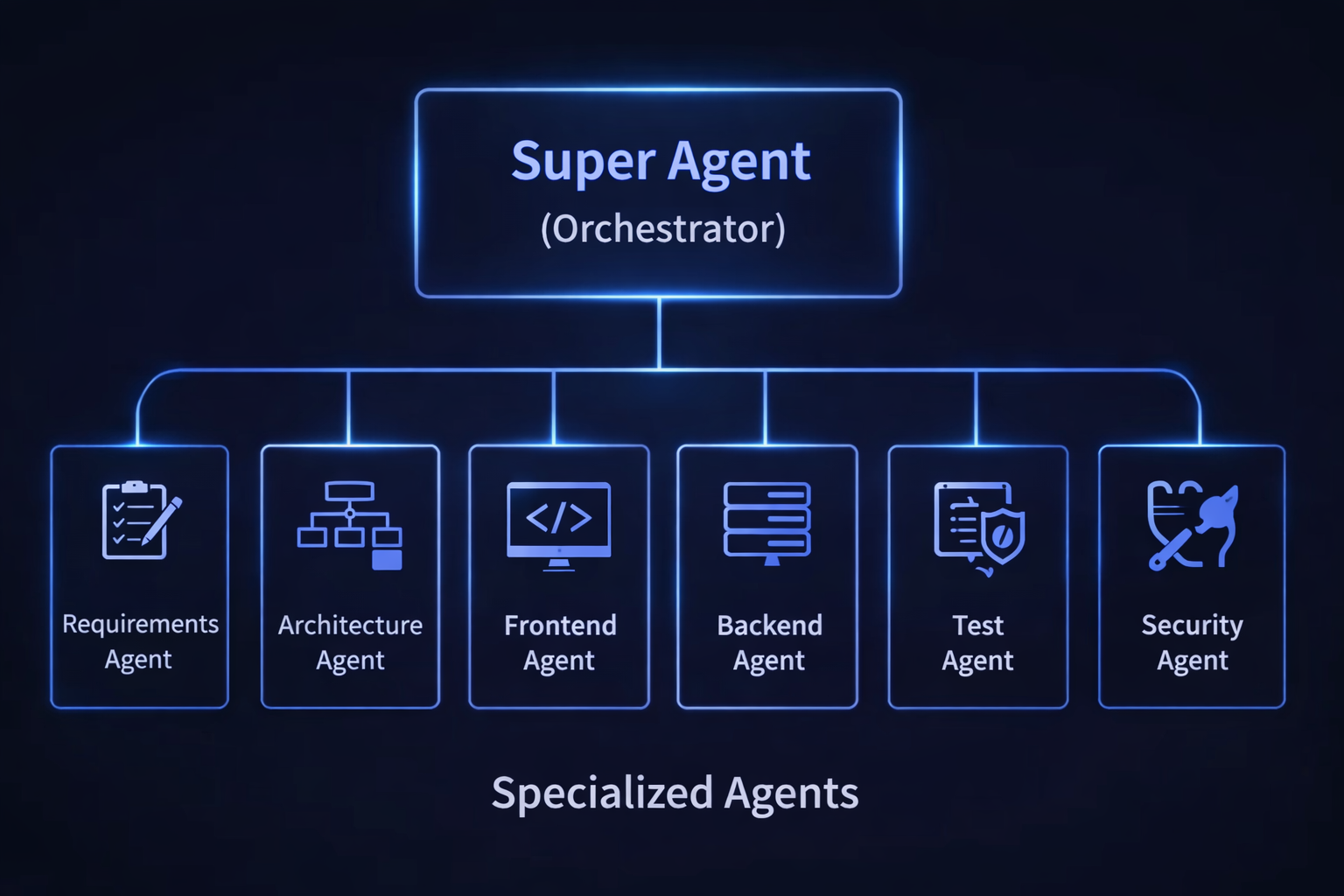
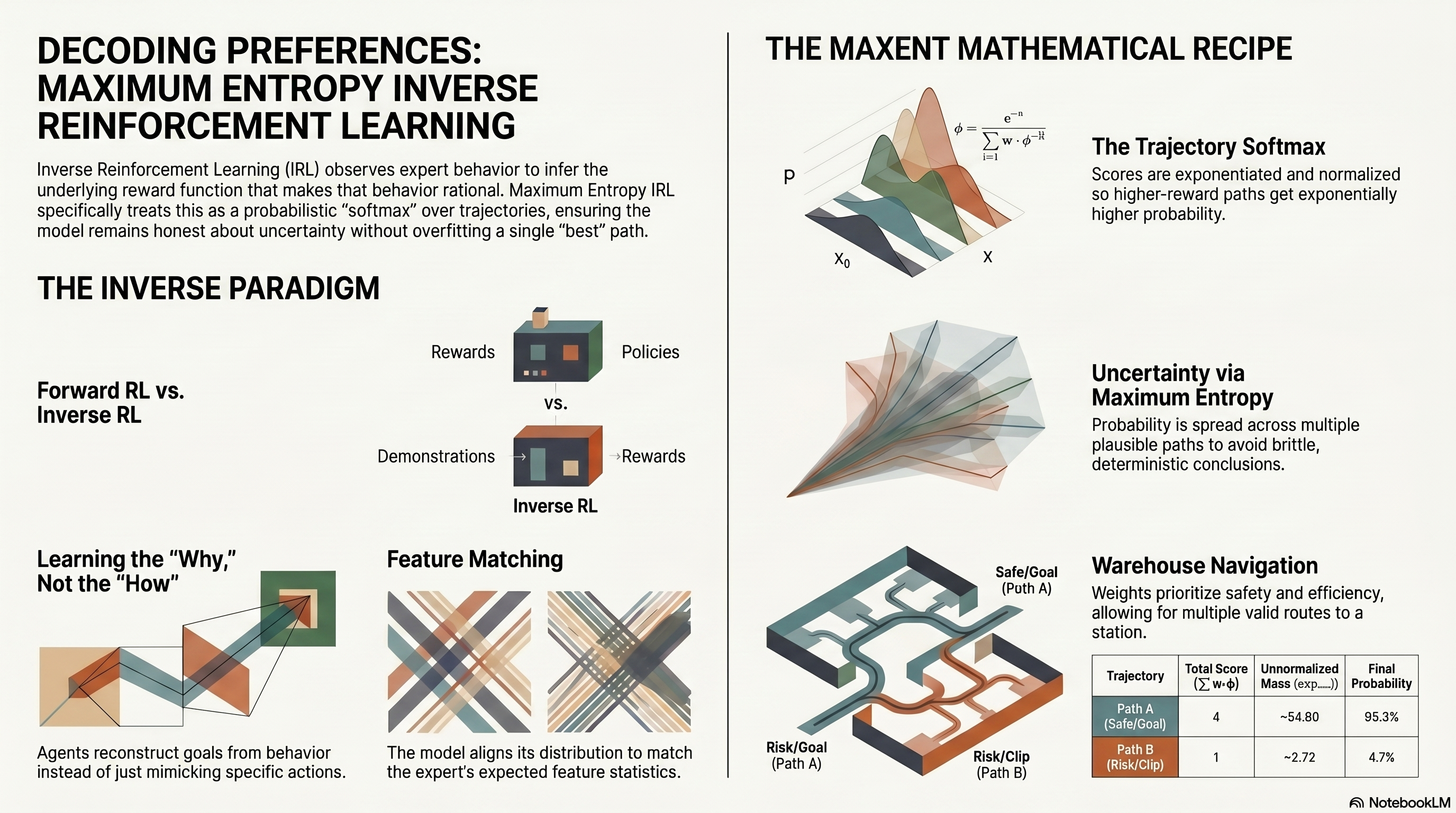
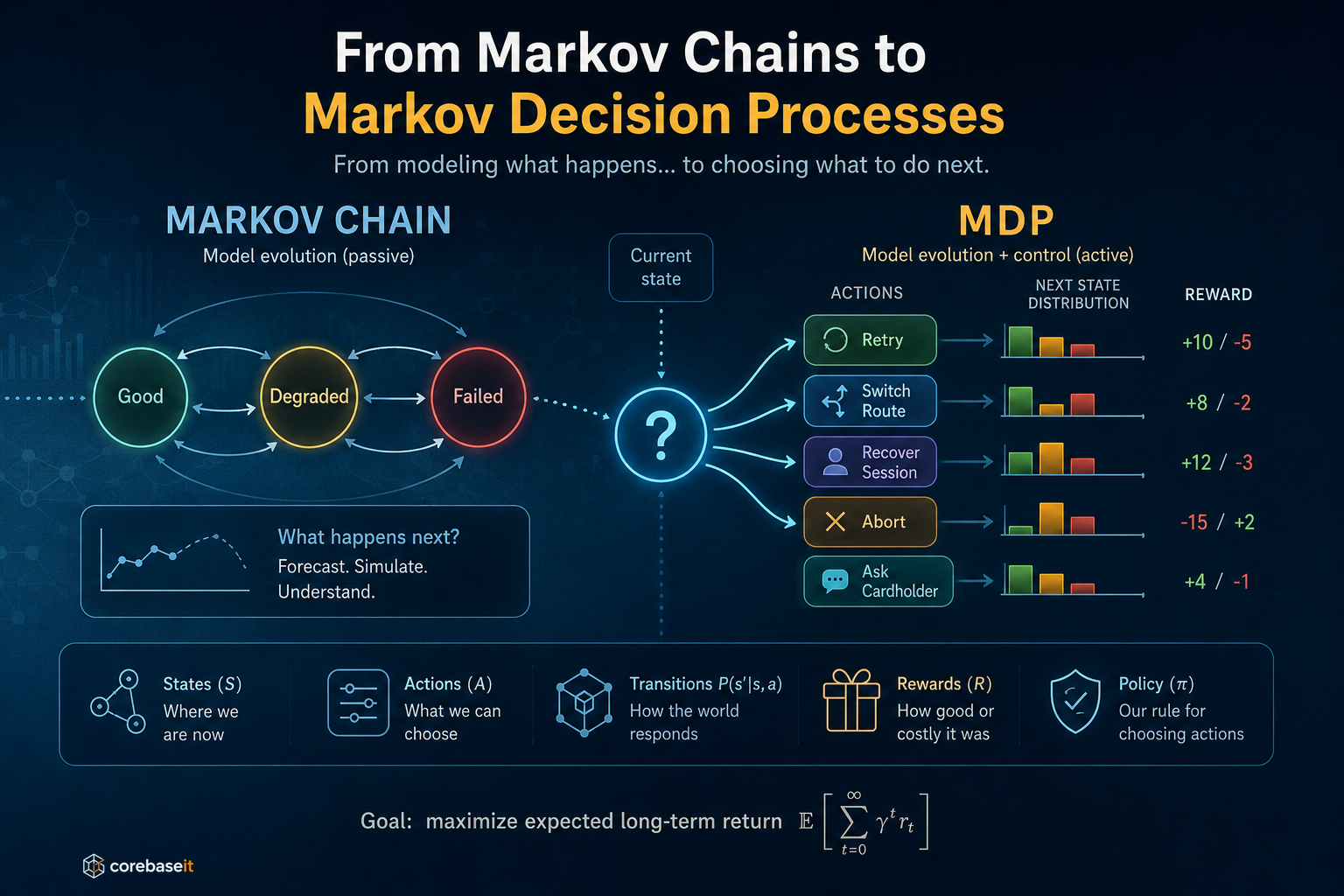
This post continues the ideas explored in Part I: Super Agents and Multi-Agent Communication and Part II: Swarm Intelligence. Those posts covered how agents coordinate within a …